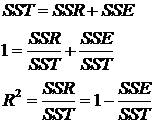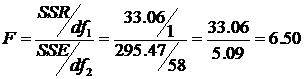Correlation and Regression
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Correlation |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Correlation – measure of linear association between two variables
|
Regression Equation |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
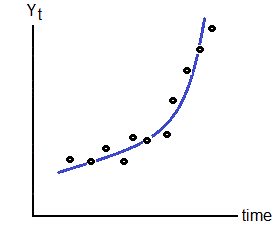
Starting with the equation
Solve for u i, which yields
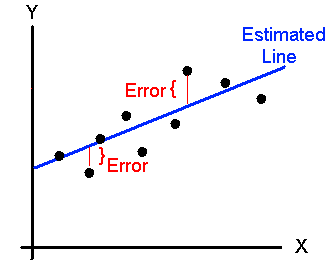
Square the errors to make them positive
This is only for one data point. We want to minimize the total errors of all the data points.
We want to find the minimum, thus we take the first partial derivatives with respect to the betas
The second step is the Chain Rule from Calculus. I can put the 2 in front of the summation because each term in the summation has a 2. Set the partial derivative to zero, in order to find minimum value
Now solve equation for b 1, It is debatable when you should add hats to the estimators. I added at this step when partial was set to zero
Summation is a linear operator. We can apply the summation to all terms in parenthesis
The last step works because we substitute the average for y and average for x into the equation. Repeating these steps to get the estimator for b 2
Similarly, set the partial to zero and solve for b 2,
We substitute the estimator for b
1 into the equation,
I did not break the last summation apart. This is to solve for the estimator for b 2
|
Goodness of Fit |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Analysis of Variance )ANOVA) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
In terms of regressions, ANOVA is used to test hypothesis in many types of statistical analysis
Y i is the dependent variable in the regression. The
This is the variation explained by the regression
SSE is the amount of variation not explained by the regression equation. Thus, SST = SSR + SSE, which is proved in the lecture.
Problem – the more parameters added to the regression, the higher the R 2. R 2 = 1, if n = k, the number of parameters equal observations Now we need the degrees of freedom for each measure: Sum of Squared Regression (SSR) df =k – 1 Sum of Squared Errors (SSE) df = n – k Sum of Squared Total (SST) df = n – 1 We calculate the Mean Square (MS) Regression (MS) = SSR / (k – 1) Residual (MS) =SSE / (n – k) Total (MS) NA
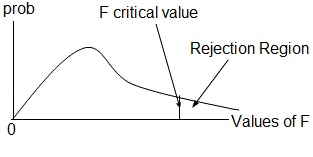
The hypothesis test H 0: Regression model does not explain the data, i.e. all the parameters estimates are zero H a: Regression model does explain the model, i.e. at least one parameter estimate is not zero First, we need the critical value: a = 0.05, df 1 = 1, and df 2 =58 In Excel, =finv(0.05,1,58) F c = 4.00 Excel calculates the ANOVA
Calculate the F-value =
The computed F exceeds the F c, so reject the H 0, and conclude at least one parameter is not equal to zero. Degrees of freedom for error df = 10 – 4 = 6
|
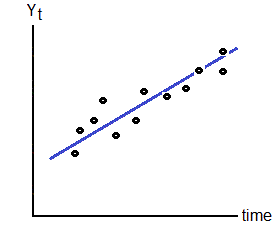
Trend Regression |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
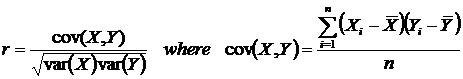
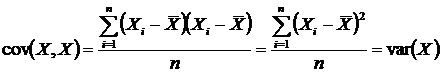
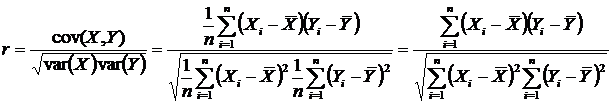


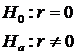
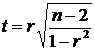




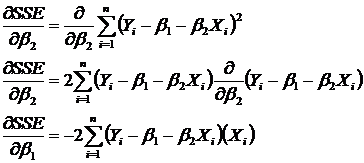



 .
.